Mini Project: RAG Pipeline Using LangChain on Databricks


By this point, I had read too much in theory about Retrieval-Augmented Generation (RAG) - what it is, how it works, and why it's useful. I understood the general processes it follows, including chunking, embedding, and vectorisation and then querying data with a large language model (LLM).
And while RAG may not be the newest concept anymore, in fact, with tools like AgentBricks, AgentForce, and N8N, it's almost become a low-code, no-code workflow. But that wasn’t the point of this project for me.
Instead, I wanted to try something hands-on that I hadn’t done before, learn by doing, and get a better understanding of how RAG actually works under the hood.
I had three main goals for building this prototype:
- Use Databricks where I work daily
Since my organisation already uses Databricks, implementing RAG within that platform makes it easier to scale for future client use cases. It also keeps the data secure within our existing environment. - Move from theory to hands-on practice
I wanted to put all the theory I'd learned into action. It’s one thing to read about embedding and vector search, it’s another to actually implement it and troubleshoot things on your own. - Try native tools like Databricks' own LLMs and
langchain-databrickscomponents
Instead of using external APIs or libraries, I specifically wanted to test what's possible natively inside Databricks, things likeChatDatabricks,DatabricksVectorSearch, andUnity Catalogintegration.
In my opinion, it is so important to understand the back-end of how things work, even at a basic level. When you understand the mechanics behind chunking or vector similarity, you’re less likely to treat low-code, no-code tools as a black box. And if things break or produce unexpected results, you would know where to look or what questions to ask.
In this blog, I will share what prototype I built, what process did I follow and some of my learnings.
What did I implement?
I implemented a basic RAG pipeline inside Databricks. Here's what I did:
- Read a PDF file directly within the Databricks notebook.
- Chunked the content into manageable sections for better context handling.
- Generated embeddings using Databricks built-in embedding model.
- Stored the vectors using
DatabricksVectorSearch, with the vector index saved in Unity Catalog. - Connected it to a Databricks-hosted LLM and enabled question answering over the document.
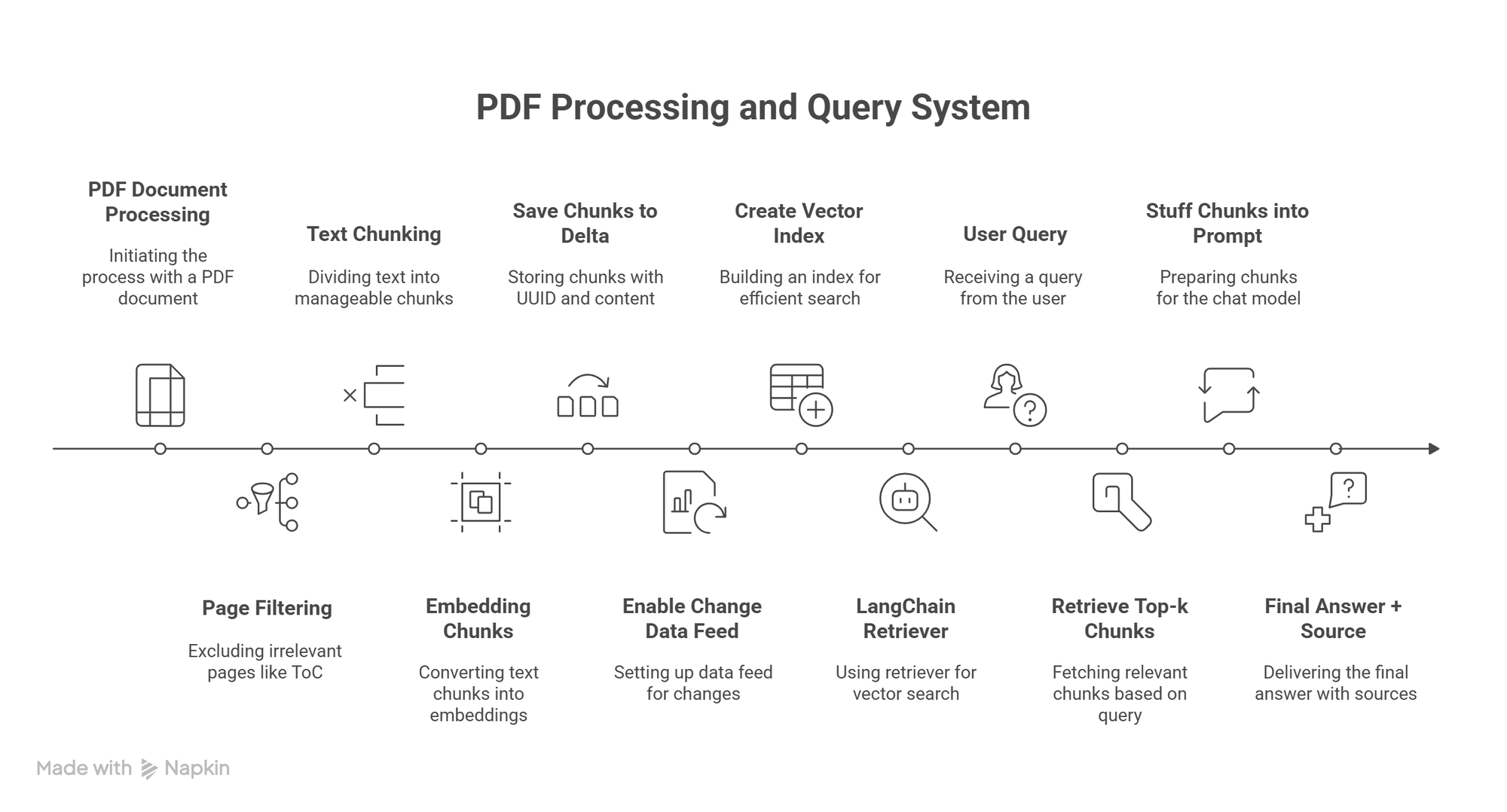
This gives users the ability to ask natural-language questions about the uploaded PDF and get context-aware answers in seconds.
But Do You Really Need a RAG Pipeline for This?
Short answer? No, not if you’re just working with a single document, parsing it once, and asking a few questions. In that case, you could easily upload the file to any AI tool like ChatGPT and chat with it directly.
But for me, this was a prototype, and the goal was to simply learn.
The real value of RAG comes in when you’re dealing with multiple documents, especially if those documents are frequently updated. In such cases, a RAG pipeline enables users to ask questions across all documents and receive relevant, up-to-date answers, without the need to manually search.
How did I implement?
1. Installing required packages and libraries
The first (and arguably most crucial) step was setting up the right environment to run LangChain within Databricks. Here's the list of packages I used:
# Installing a specific version of LangChain to ensure compatibility
%pip install langchain==0.1.20
# Installing Pydantic v1 (v2 has breaking changes with LangChain)
%pip install pydantic==1.10.7
# Databricks' GenAI SDK – allows integration with native Databricks LLMs
%pip install databricks-genai
# Enables the use of Databricks-native vector search APIs
%pip install databricks-vectorsearch
# For reading and parsing PDF files
%pip install pymupdf
# Adds Databricks-native LangChain integrations (e.g., ChatDatabricks, VectorSearchRetrieverTool)
%pip install databricks-langchain
LangChain was not working due to version conflicts with pydantic. For this, I installed a specific version of langchain==0.1.20 and a specific version of pydantic==1.10.7 which are compatible with each other.
Once installed, I imported the required modules:
from langchain.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import DatabricksEmbeddings
from databricks.vector_search.client import VectorSearchClient
from langchain.vectorstores import DatabricksVectorSearch
from databricks_langchain import VectorSearchRetrieverTool, ChatDatabricks
from langchain.chains import RetrievalQA
from pyspark.sql import SparkSession
import uuid2. Upload PDFs in Unity Catalog (via Volumes)
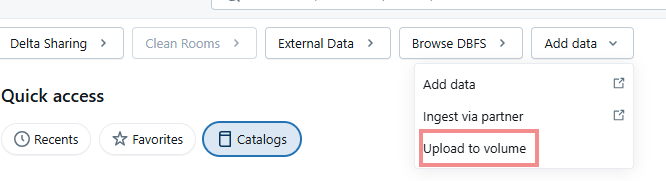
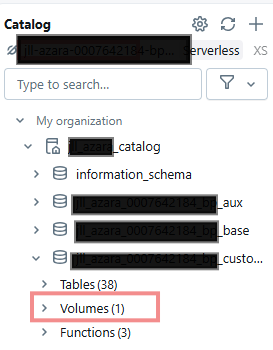
Then uploaded the PDF (unstructured data) in Unity catalog by creating Volumes.
To create a volume, go to the Catalog > Add Data > Upload to Volume.
If a volume is created for you already, you can simply upload your documents, if not, it will give you an option to create a volume, just give it a name and path.
3. Load data in LangChain Document format
LangChain requires documents to be in its standard Document format. Loaders help convert raw files (like PDFs) into this format for further processing.
In my case, I used PyMuPDFLoader to read the PDF stored in Unity Catalog:
# Replace with your actual volume path
pdf_path = "/Volumes/catalog/schema_name/volume/YourDocument.pdf"
loader = PyMuPDFLoader(pdf_path)
documents = loader.load()
print(f"Loaded {len(documents)} page(s) from the PDF.")The PDF I used had text, images, and tables. PyMuPDFLoader only extracts text, it ignores images and tables, which was fine for my use case focused on text-based Q&A.
I also excluded the cover page and table of contents manually before passing the data to the next stage.
# Exclude cover (page 0) and ToC (page 1)
relevant_pages = documents[2:] 4. Chunking the PDF
Once the document is loaded, the next step is chunking. It is the process of breaking down text into smaller segments so that they are big enough to contain meaningful information but small enough to fit within the context window of LLM.
While there are several chunking techniques available, I used the most common one for this prototype which is Recursive Character Text Splitter.
splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=100,
separators=["\n\n", "\n", ".", " "]
)
chunks = splitter.split_documents(relevant_pages)
print(f"Created {len(chunks)} chunks.")The way it works is:
- It first attempts to split text on paragraph breaks (
\n\n). - If the resulting chunk is still too large (greater than 800 characters), it tries splitting by new lines (
\n). - If it's still too big, it moves on to full stops (
.), and then spaces ( - It keeps doing this recursively until each chunk fits within the 800-character limit.
Chunk overlap parameter (chunk_overlap=100) is used to preserve context across chunks. Let’s say a key sentence is split between two chunks, with a 100-character overlap, the ending of one chunk is carried over into the next. This reduces the chance of the model missing critical information during retrieval.
5. Save Chunks to DeltaLake
Once the document is chunked, the next step is to store those text chunks somewhere. To do that, I first converted each chunk into a dictionary format and then wrote it as a Delta table which is a reliable place to store all the chunked content before generating embeddings.
catalog = "<your-catalog-name>"
schema = "<your-schema-name>"
index_name = "<index-name>" # Give a suitable index name
spark = SparkSession.builder.getOrCreate()
# Convert chunks to a list of dicts
rows = [{
"id": str(uuid.uuid4()), # or chunk.metadata['page'] if useful
"page_content": chunk.page_content
} for chunk in chunks]
# Create DataFrame and write to Delta
df = spark.createDataFrame(rows)
df.write.format("delta").mode("overwrite").saveAsTable("catalog.schema.index_name")
6. Create Embedding (via Vector Index)
Now comes the part where we generate embeddings, which means converting the chunks into numerical representations that an LLM can understand. In Databricks, the embeddings are automatically created when we build the vector index, using a model like databricks-bge-large-en.
But before we do that, we need to create a Vector Search Endpoint in Databricks. You can do this by going to Compute → Vector Search → Create Endpoint

This can take a few minutes before the vector endpoint is ready for use. Once ready, we can create our vector index.
from databricks.vector_search.client import VectorSearchClient
client = VectorSearchClient()
catalog = "<your-catalog-name>"
schema = "<your-schema-name>"
index_name = "<index-name>" # Choose a relevant name
full_index_name = f"{catalog}.{schema}.{index_name}"
vs_index = client.create_delta_sync_index(
endpoint_name="your-endpoint-name", # The one you created earlier
index_name=full_index_name,
source_table_name="catalog.schema.index_name",
pipeline_type="TEXT_EMBEDDING",
embedding_source_column="page_content",
embedding_model_endpoint_name="databricks-bge-large-en"
)This code reads the data from the Delta Table, sends the page_content (our chunks) through the embedding model and stores the embeddings in a vector index, which we’ll use to search and retrieve relevant chunks in the next step.
8. Connect Vector Store to Retriever
A retriever helps fetch the most relevant chunks (based on similarity) for a given user query. This retriever is looking at our Delta Table and would be able to search for relevant information in it based on user's question.
# Connect to the vector store
vector_store = DatabricksVectorSearch(
endpoint="test_vector", # This is your vector search endpoint
index_name=full_index_name, # Full index path: catalog.schema.index_name
)
# Convert the vector store into a retriever object
retriever = vector_store.as_retriever()
# Load a Databricks-supported LLM
chat_model = ChatDatabricks(
endpoint="databricks-meta-llama-3-70b-instruct", # LLM endpoint
temperature=0.1, # Controls creativity
max_tokens=500 # Limits length of response
)
# Build the retrieval-based QA chain
qa_chain = RetrievalQA.from_chain_type(
llm=chat_model,
retriever=retriever,
chain_type="stuff", # The simplest type – it stuffs all retrieved docs into a prompt
return_source_documents=True # Lets us trace where the answer came from
)
9. Ask a Question
Final step is to define a simple function that allows users to ask questions.
It uses the qa_chain above to return both the answer and the source documents used to derive that answer.
def ask_ccr_question(query):
response = qa_chain(query)
return {
"answer": response["result"],
"sources": [doc.metadata for doc in response["source_documents"]]
}
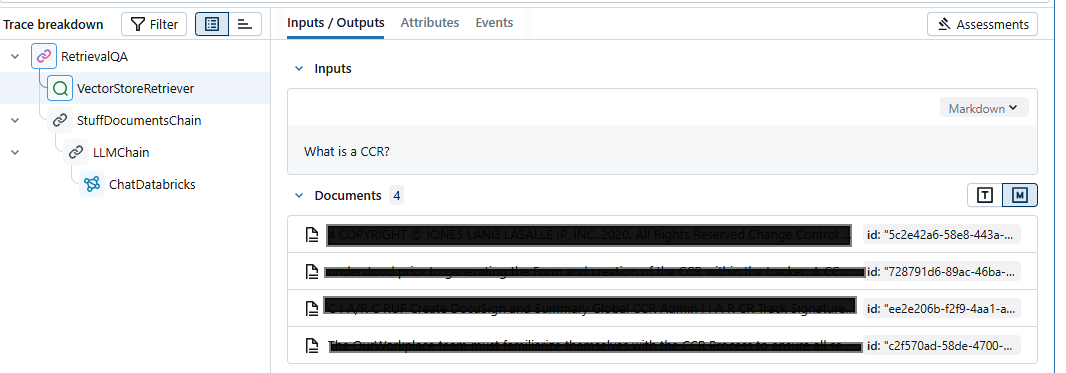
ask_ccr_question("What is a CCR?")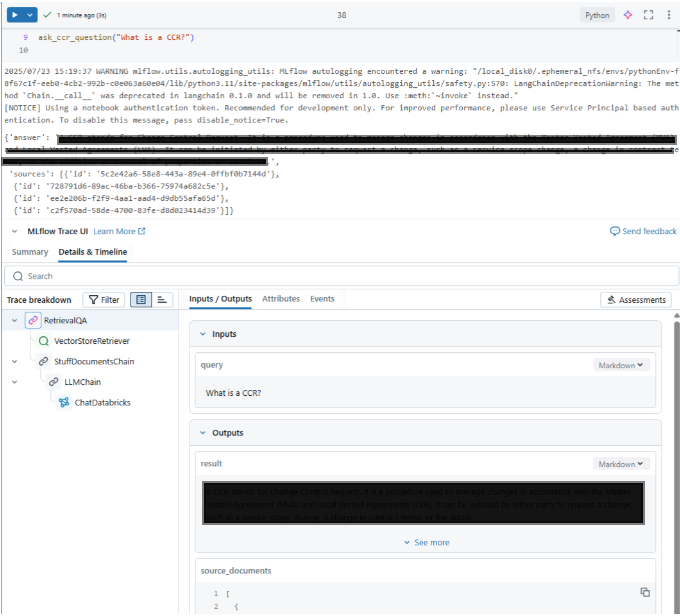
Closing
This little project has opened up possibilities to implement such use cases for our clients. Even thought RAG might be old school now, but if we can guarantee security and deliver the use case efficiently, I genuinely believe clients would still prefer it. The best part is that I can even give this a simple front-end using Databricks’ built-in app deployment feature — which makes the whole solution more accessible. I’m looking forward to refining it further and exploring how it could be shaped into something truly useful.